

In the last chapter, we introduced the concept of dependency. In this chapter, we will look into it and see how we can utilize this concept in factorization.
Left-looking Cholesky factorization
Particularly, we will use the Left-Looking Cholesky Factorization. In the left-looking Cholesky factorization, we compute the factor 




In practice, we can fold together these two expressions above into a single matrix-vector multiplication and addition. We call 

Another Cholesky method is the Up-Looking Cholesky Factorization.
Overview of sparse factorization
For sparse factorization, we usually go through two phases:
- Symbolic Analysis: Analyzing the non-zero pattern of matrix
- Numerical Factorization: Computing the numerical values in

Elimination tree
The elimination tree (etree) of the matrix is a pruned version of the Dependency Graph 
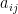
Although it looks like the path is longer than a single edge, remember that we are not trying to find the shortest path. We are trying to find a minimal graph that can represent the dependencies or the order of computation, and the path can cover more dependencies than a single edge. Intuitively, you can visualize the algorithm as only keeping each column’s topmost non-diagonal non-zero entry.

Thinking question: why does selecting the longer path make you select the smallest/topmost non-diagonal entry?

With etree, you can easily find the dependencies of node j (the nodes that need to be computed before j) by traversing down the descendants, and find the nodes that will be affected by node j by traversing up the ancestors. Therefore, we can determine that the order of computation is from the leaves of the tree to the root.
The elimination tree is stored as an array of parents, where parents[i] is the parent node of the node i.
Constructing the elimination tree
The etree describes the dependency pattern of the factor cs_etree for details).
We iterate over the columns in the upper triangular matrix of
The iterative computation of the etree is as follows:
Suppose
Davis, 2006(the etree of submatrix
) is known. This tree is a subset of
. To compute
implies the path
exists in T , this path can be traversed in
Beyond this, To speed up the subtree traversal (all nodes within the path started from i will be rooted at k), we keep an array of ancestors, and set ancestors[i] = k to put the subtree 


parents, yellow lines show the ancestors.The row subtree of node k,
Node j is a leaf of
Davis, 2006and
for every descendant i of j in the elimination tree
.
Post-ordering
One simple trick to improve the performance of the factorization is post-ordering. After building the elimination tree, we can permutate the matrix
For example, in the figure above, the etree will guide the computation to follow the order 

The postordering of an etree can be easily found by performing a depth-first search. Column j will be moved to i where i is the tree node’s position’s order of traversal during a DFS.
Permutation
In this context, permutation means switching nodes’ order; this is feasible because the real problem focuses on the relationship (edges) of the nodes, not their ordering. We can store the permutation of 


Non-zero patterns
Fill-ins
When factorizing a matrix, it will create some non-zero entries in the factor that does not exist in the original matrix (the crossed dots in Figure 2). We can these new entries the fill-ins. We can do a Cholesky factorization to see how they appear.
A key observation of the non-zero pattern in the factor is:
l_{ji} \neq 0 \text{ and } l_{ki} \neq 0 \Rightarrow l_{kj} \neq 0
For a matrix
\bold{l_k} = (\bold{a_i} - \bold{L_2} \bold{I_1^\intercal}) / l_{kk}Particularly, given that 







In other words, given three nodes 


Fill-reducing ordering
The fill-ins increase the amount of computation; by permutating the nodes prior to computing the elimination tree, we can reduce the number of fill-ins. The fill-in minimization problem is NP-hard, so we usually use heuristics.

Nested dissection ordering
Nested dissection ordering is a fill-reducing ordering that is useful in the field of computer graphics. We can use an analogy: “Moving your toes does not affect your head”.
Nested dissection ordering finds a list of nodes as a separator (for example, the “waist” from the analogy above), and then puts the nodes that are closely connected, and separated by the separator, near each other (“leg” with “feet”, “head” with “neck”). The separated part can then dissect recursively.
The goal of the ordering is to build a balanced etree, the dissected parts will be two disjoint subtrees, and they join together by the separator. As an effect, the matrix will result in a block structure, where there are no edges between each block.

References
Davis, T. A. (2006). Direct methods for sparse linear systems. Society for Industrial and Applied Mathematics.
Davis, T. A., Rajamanickam, S., & Sid-Lakhdar, W. M. (2016). A survey of direct methods for sparse linear systems. Acta Numerica, 25, 383–566. https://doi.org/10.1017/S0962492916000076
Herholz, P., & Alexa, M. (2019). Factor once: reusing cholesky factorizations on sub-meshes. ACM Transactions on Graphics, 37(6), 1–9. https://doi.org/10.1145/3272127.3275107